
Exploring AI Agents with Oracle’s Generative AI Agents Platform
Published:

1. Introduction
AI Agents are intelligent systems capable of autonomously performing tasks, making decisions, and interacting with users or other systems. They are widely used to automate processes and enhance user experiences across domains like customer support, data analysis, and content generation. While their applications are broad, providing a precise, universally accepted definition of AI agents remains challenging due to the evolving nature of the field.
In this context, we define an “AI agent” as an artificial intelligence system composed of the following components:
- Goal and Role: The specific task or objective the agent aims to accomplish.
- Brain: The underlying algorithm, often a large language model (LLM), that drives the agent’s autonomous decision-making and input/output processing.
- Memory and learning: The agent’s ability to store and retrieve past information, improving its performance over time through short-term and long-term memory. Often, this is achieved through in-memory storage or external databases.
- Tools: The actions or functions (e.g., APIs, databases) the agent uses to accomplish its tasks.
- Interaction protocol: How the agent communicates with users or other systems, such as through a chat interface, event-based models, or API calls.
- Guardrails: Rules that restrict the agent’s behavior to ensure it operates safely and within defined limits, particularly important for security and preventing harmful actions.
- Orchestratior: Coordinates the agent’s components to ensure they work together effectively, often involving a Q&A system that manages user interactions and data retrieval. Usually, that is implemented using frameworks like LangChain or LlamaIndex.
2. AI Agents on Oracle Cloud Infrastructure
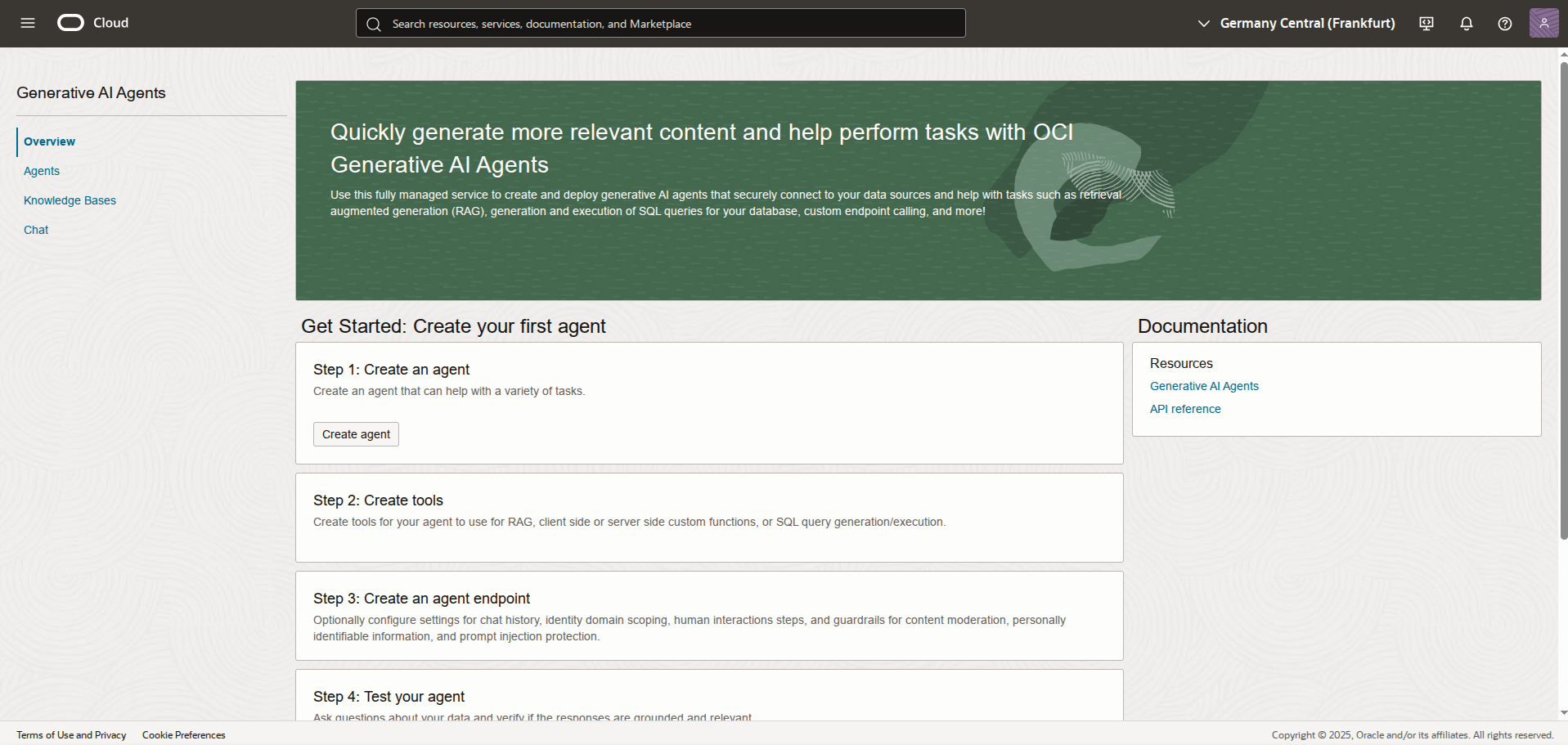
Oracle has recently launched its new OCI Generative AI Agents Platform (Figure 1), which allows users to create and deploy AI agents capable to perform a wide range of tasks, including answering questions, providing recommendations, and automating processes. The platform is designed to simplify the development and deployment of AI agents, providing a set of pre-built tools for the most common tasks, but also allowing users to create custom tools to extend the functionality of their agents.
Key features of the OCI Generative AI Agents Platform include:
Agent Definition and Deployment: A complete environment for defining and deploying AI agents.
Pre-built and custom tools: RAG (Retrieval-Augmented Generation), which enables agents to retrieve relevant information from a knowledge base, and NL2SQL (Natural Language to SQL), which allows agents to convert natural language queries into SQL for interacting with databases and retrieving structured data. Also, users can integrate their own tools to extend agent functionality.
Context Retention: Agents can store and recall past conversations, maintaining continuity.
Guardrails and content moderation: Implement rules to control agent behavior, ensuring operation within defined boundaries and preventing harmful actions.
Human-in-the-Loop: Incorporate human oversight and intervention when needed.
Additional information on the OCI Generative AI Agents Platform can be found in the official documentation and the Oracle AI & Data Science Blog.
3. Building a Basic RAG Agent with the OCI Generative AI Agents Platform
The goal of this article is to build a simple Retrieval Augmented Generation (RAG) chat assistant using the OCI Generative AI Agents Platform. The assistant is designed to answer questions about bad writing patterns in Docker files, namely Dockerfile smells, using research papers as source of knowledge. The data is uploaded to an Oracle storage bucket, and the OCI platform handles the rest (uploading, parsing, ingestion, agent logic, and deployment) without requiring writing any line of code.
3.1 What is RAG?
RAG is a powerful approach that combines the strengths of retrieval-based and generation-based methods to provide more accurate and contextually relevant responses.
Simply, the RAG approach is composed of a source knowledge base, which can be a set of documents, a database, or an API, and a Large Language Model (LLM) that is used to generate the responses based on the retrieved information. The key idea behind RAG is to leverage the in-context learning capabilities of LLMs to generate responses requiring information that is not present in the training knowledge of the model.
The RAG approach is particularly useful in scenarios where the information is constantly changing or evolving, such as in the case of scientific papers, news articles, or technical documentation. By using RAG, it is possible to create AI agents that have up-to-date information based on the latest data available in the source knowledge base, without the need to retrain the model.
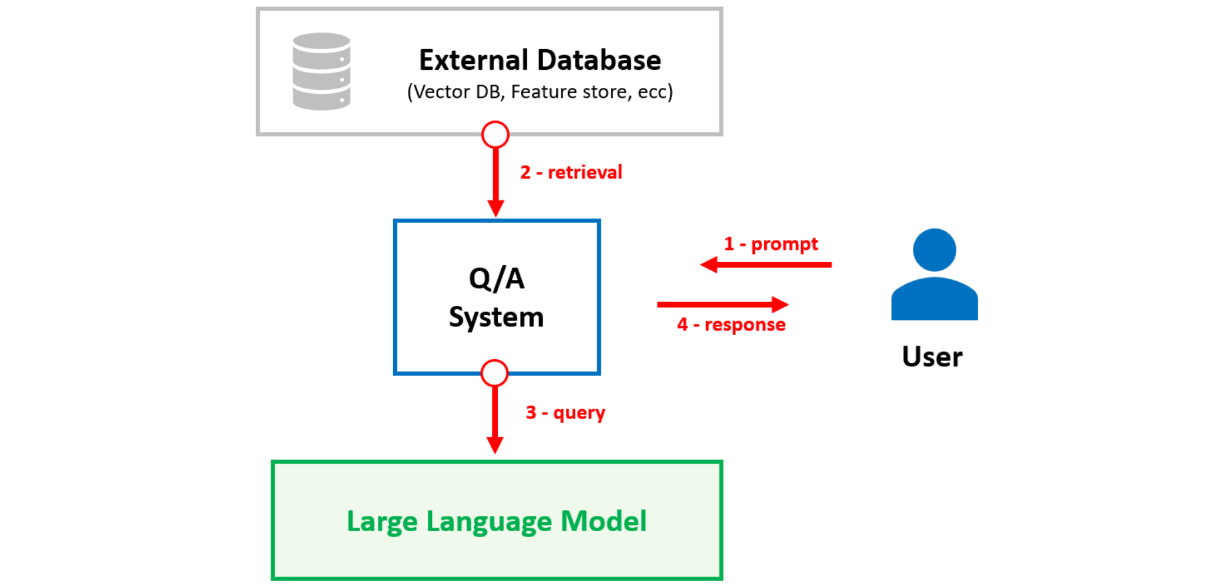
Figure 1 shows the architecture of a RAG system, which is composed of three main components:
- Knowledge Base: This is the source of information that the agent will use to retrieve relevant data. A common approach is to use a vector database, able to store and retrieve information based on the semantic similarity between the query and the stored data.
- Q&A system: Orchestrates the interaction between the user and the knowledge base. It is responsible for processing the user queries, retrieving relevant information from the knowledge base, and generating the responses using an LLM.
- LLM: The language model that is used to generate the responses based on the retrieved information. The LLM can be a pretrained foundation model or a fine-tuned model specialized for information retieval tasks, or a specific application domain.
4.1 Preliminary steps
To access the OCI Generative AI Agents Platform, an Oracle cloud account is necessary. While the service isn’t free, new users will receive free credits for testing the platform. Moreover, OCI offers a free tier that includes a limited set of services, which can be useful for experimenting with the platform and testing the capabilities of the agents. To create an account, visit the OCI website. OCI is organized into regions, and not all regions offer the complete set of services. For users based in Europe, a good choice is the Germany Central (Frankfurt) region, which will be used in the examples provided in this article.
A recommended best practice before using OCI services is to create a compartment to isolate and manage the resources for a specific project. This approach helps organize resources, control access, and monitor costs more effectively. By setting a spending threshold and configuring alerts, you can track expenses and receive notifications when the threshold is exceeded.
4.2 Preparing the knowledge data
As mentioned, the knowledge base for our agent will consist of research papers related to Dockerfile smells. Specifically, we will use a paper by Rosa et al. [1]. This study investigates which Dockerfile smells are most frequently fixed by developers in the open-source domain, aiming to identify the most important smells to avoid when creating Dockerfiles.
Before setting up the agent, we need to create a storage bucket in which we upload the PDF of the paper, to make it available for the agents platform. A storage bucket is a container that allows us to store and organize data in the Oracle Cloud Infrastructure (OCI) Object Storage service. A guide on how to create a storage bucket can be found in the official documentation.
The next step is to start with the agent creation process via the Generative AI Agents platform.
4.3 Defining the agent logic
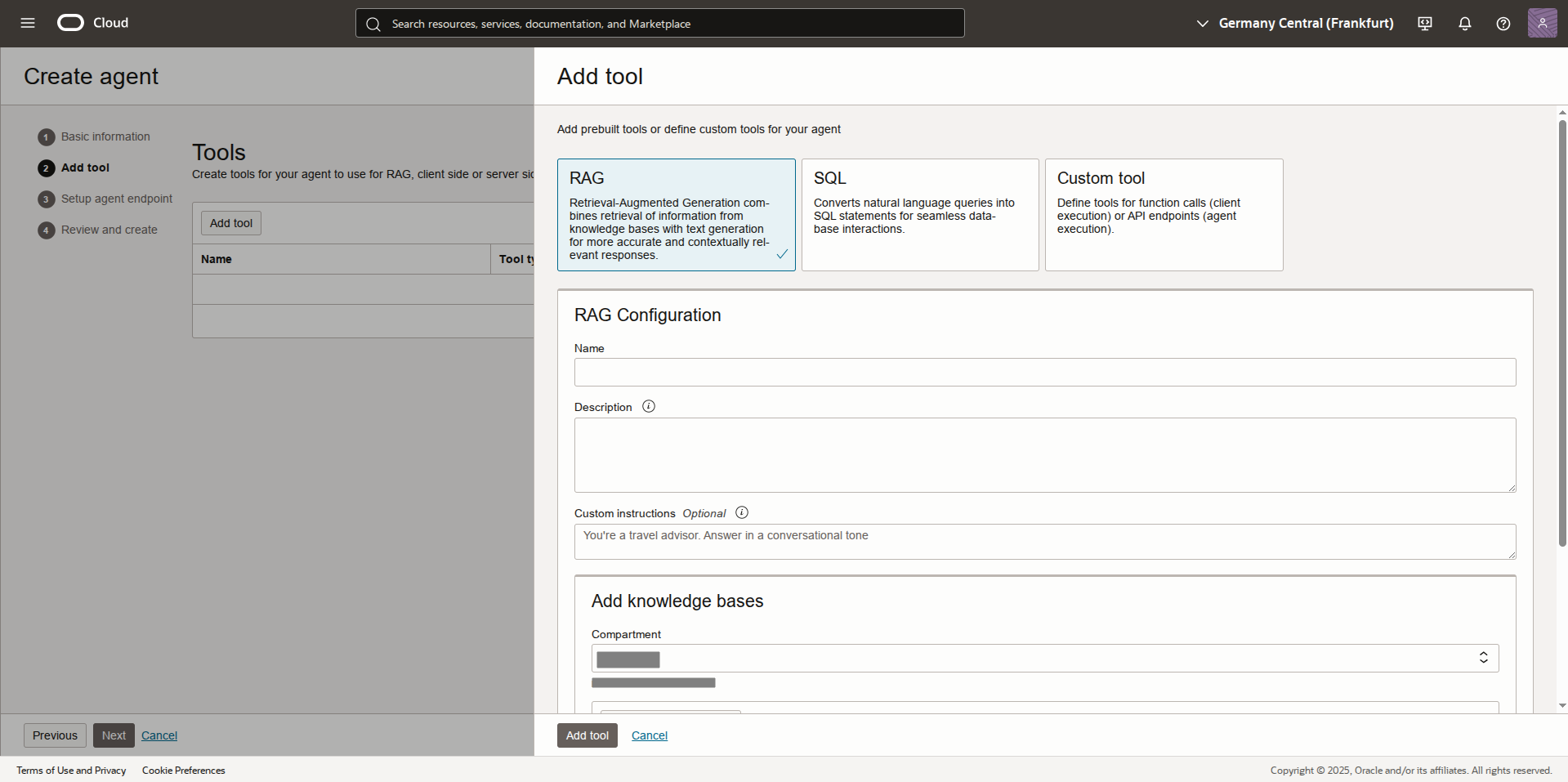
After accessing the Generative AI Agents platform, we can start creating our agent by clicking on the “Create Agent” button (Figure 1). The first section requires some basic information about the agent, such as the name and a welcome message. A good practice is to provide a brief description of the agent’s capabilities and the topics it can cover, so that the user knows what to expect from the agent.
In the next section, Add tool, select the RAG tool (Figure 3). Here, assign the knowledge base by choosing one of the available source options. For this example, we use the Object Storage option and specify the previously uploaded PDF file as the data source (Data sources > Specify data source).
Finally, marking the “Automatically start ingestion job for above data sources” checkbox, the platform will execute an ingestion job automatically, which processes the PDF file, extracting and processing the text in a format that can be used by the agent. The ingestion process can take some time, depending on the size of the files and the complexity of the data.
4.4 Configuring the agent endpoint
At this point, we have a knowledge base that contains the information we want to use to answer questions related to Dockerfile smells. We can verify it by visiting the “Knowledge Bases” tab. The final step is to configure the agent endpoint settings, which define how users will interact with the agent.
First, ensure that the “Automatically create an endpoint” checkbox is selected. This will generate an API endpoint at the end of the procedure, enabling interaction with the agent through the chat interface.
Additionally, we can configure extra features for our endpoint, such as content moderation, protection against malicious requests (e.g., prompt injection), and the removal of sensitive information from input and/or output responses (such as personally identifiable information, PII).
The latter is especially important when handling sensitive data, as it helps ensure the agent does not inadvertently expose confidential information in its responses.
4.5 Run and test the agent
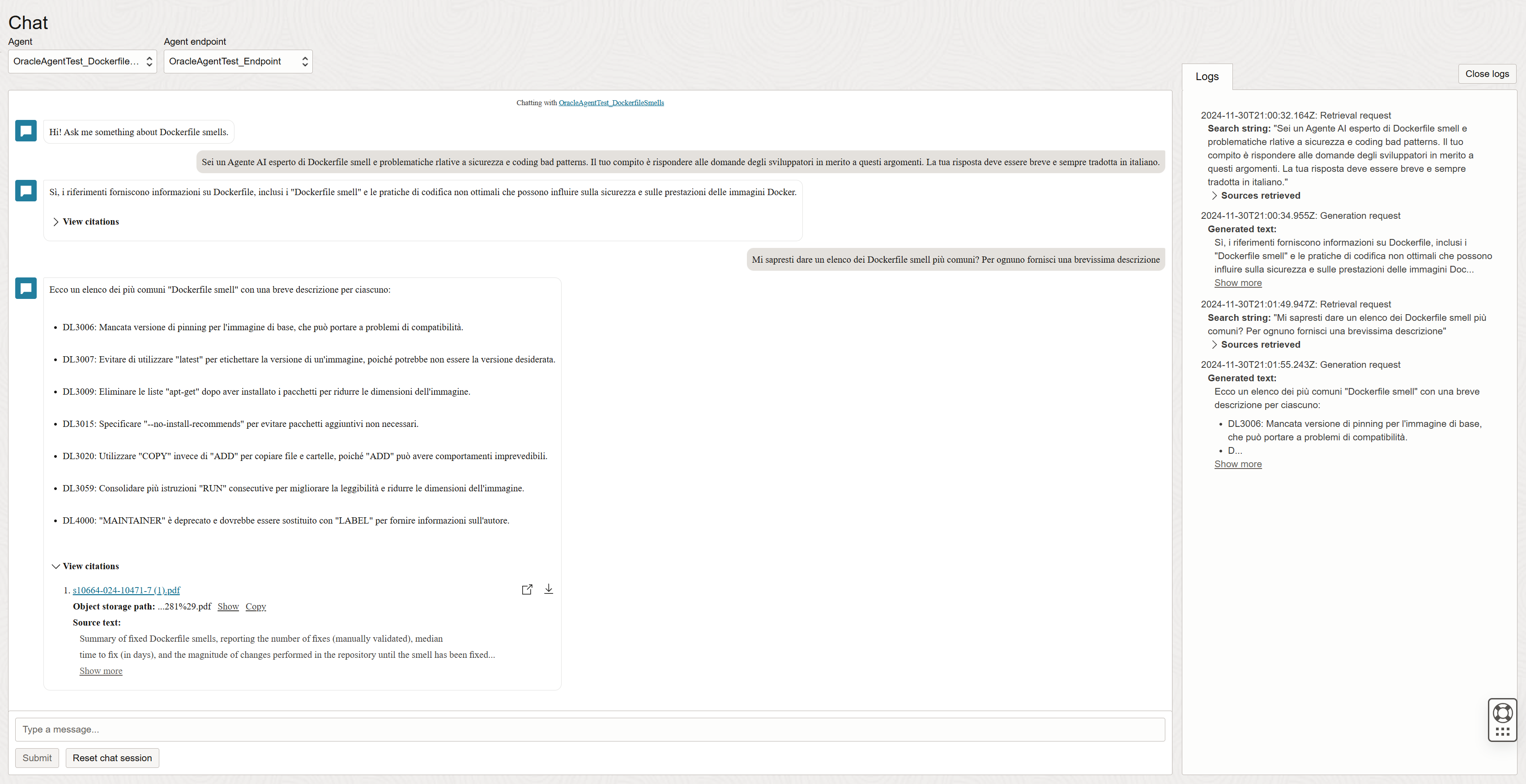
Now everything is ready to test our agent! From the Generative AI Agents > Chat tab, you can interact with the agent using the chat playground interface.
Our agent is now an expert on Dockerfile smells, thanks to the knowledge base we created, so we can ask questions related to that topic.
Before starting, make sure that the agent and the endpoint created in the previous steps are selected in the top left corner.
The chat playground does not require any programming knowledge, as it provides a user-friendly interface for interacting with the agent. For advanced integrations or customizations, the platform also provides an API that can be used to interact with the agent programmatically via the OCI SDKs or directly through HTTP requests.
Our agent is using English for interactions, matching the language of the welcome message and the user input. It is recommended to keep the knowledge base in a language in which the agent’s LLM is proficient (such as English) to ensure more accurate and reliable responses. To change the response language, you can instruct the agent to reply in Italian and to keep the answer brief and concise (see Figure 4). The agent will then retrieve relevant information from the knowledge base and generate a response translated in Italian.
Continuing with the example, we ask the agent to provide a list of the most common Dockerfile smells, each accompanied by a brief description. The agent retrieves the relevant information from the knowledge base and generates a response that includes this list. Additionally, the platform allows us to view a log of the interactions, detailing the sources used. This feature is useful for understanding how the agent arrived at its answer and for verifying the accuracy of the information provided (see Figure 4).
5. Conclusion
In this post, we explored how to create a RAG agent using the OCI Generative AI Agents Platform. We began by defining AI agents and their applications across various domains. Next, we introduced the RAG approach, which combines retrieval-based and generation-based methods to deliver more accurate and contextually relevant responses. All without writing any line of code.
As the OCI Generative AI Agents Platform continues to evolve, some content in this post may become outdated. However, the goal is to provide a basic example of creating an agent, which can be further extended and customized for specific needs.
For the latest updates and features of the OCI Generative AI Agents Platform, always consult the official documentation or seek professional support for advanced use cases.
References
[1] Rosa, G., Zappone, F., Scalabrino, S., & Oliveto, R. (2024). Fixing dockerfile smells: An empirical study. Empirical Software Engineering, 29(5), 108.
*Please note: All screenshots are intellectual property of Oracle and used in accordance with their copyright guidelines.